说些废话
对于这个项目的实现
前言
论文名:RKT:Relation-Aware Self-Attention for Knowledge Tracing
链接:
- 论文链接 https://arxiv.org/pdf/2008.12736.pdf
- 代码链接 https://github.com/shalini1194/RKT(文章公开了一个包含题目描述的数据集)
- 文章介绍链接:(知乎)https://zhuanlan.zhihu.com/p/476672880
1. 相关背景
从本质出发,这篇文章 对于 遗忘效应 以及 题目相关性计算上提出了较新的方式
1.1 核心思想
遗忘效益
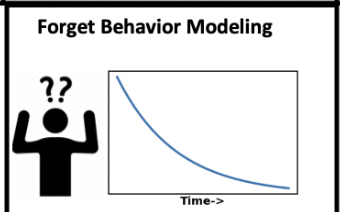
随着时间的流逝 time的变化 会随着时间 不断的流逝 对于公式的体现
图!
题目相关性
题目的词向量转换
图!
通过余弦相似度 来计算 对应的 文本的相似性
作答数据 相关性计算
图!
训练关系矩阵计算
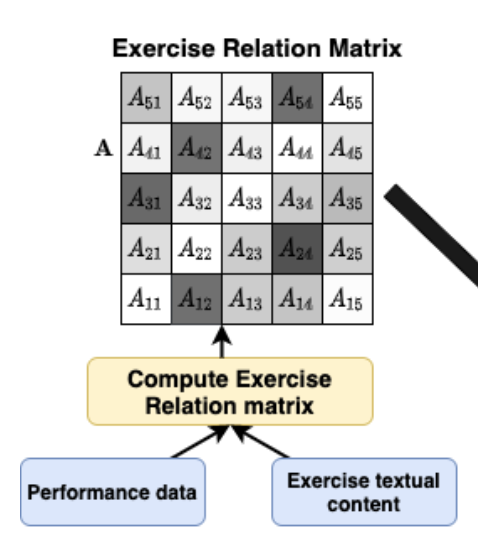
图!
2. 实证分析
3. 问题描述
正常的知识追踪方法
4. 方法(基本为论文方法部分)
我们已经得到了训练的A矩阵,以及上述的遗忘的阶段计算出来的 RT
图!
RT 为 训练题目相关的向量(类似于 我求了一个序列 对于最后答案的贡献度)
数据输入
图!
E 为 题目编码的向量
rj 为 长度为d 题目正确与否的扩充
p 为 位置编码